Meta
SKRIV att det är SLASK. OFÄRDIGT! Ska REDIGERAS!
Jag fick iden när jag såg nyhetsartikeln om Peter Lundgren. Jag tror att det kom samma dag som uttalandat. Trots det har det tagit flera månader att skriva klart. Nu är det ganska inaktuellt.
Jag har läst igenom vad jag har skrivit. Tycker att det är lite halv-bra. Varför skriver jag så mycket om statistisk analys om jag ändå använder en färdig implementation? Vem är målgruppen? Jag brukar tänka mig att målgruppen är jag själv, men innan jag har läst och tänkt på ämnet. Det är inte särskilt begripligt för dem som inte har sett hypotesprövning, och för detaljerat för dem som har. Dessutom tror jag att jag kan ha blandat ihop ensidig och tvåsidig hypotesprövning. Det påverkar inte slutsatsen, men kanske ger ett dåligt intryck.
Jag kan inte bestämma mig för om texten handlar om statistik, eller om nyheten runt norsk TV och Peter Lundgren. Jag kanske ska testa dela upp den i två?
Nån slags inledning
Sverigedemokraternas toppkandidat i EU-valet 2019 Peter Lundgren sade nyligen följande i en SVT-utfrågning:
[…] samtidigt ska man ha i åtanke att under de senaste 18 åren, har inte medeltempearaturen på jordytan ändrat sig. Den ligger konstant. Och det är fakta ifrån FNs klimatpanel.
Programmet var en del av SVTs valserie Toppkandidaterna. Det kunde fram till strax efter valet ses här på SVT play. Nu i efterhand måste man betala 1250 kr för att få en vattenmärkt digital fil skickad till sig. Programmet kunde ses kl 19.30 på SVT2 den 16e maj 2019 (viktigt att veta om man vill hitta det efter att programmet blir låst på SVT Play). Det ska också gå att se på programmet på Kungliga Biblioteket.
Jag skriver ut citatet med lite mer kontext:
– Forskare är eniga om att det är bråttom. Utsläppen måste minskas drastiskt inom 10 år. Tror du på det?
– Det tror jag på. Men samtidigt ska man ha i åtanke att under de senaste 18 åren, har inte medeltempearaturen på jordytan ändrat sig. Den ligger konstant. Och det är fakta ifrån FNs klimatpanel. Ska vi få ner CO2-utsläppen, så är det ett obestridligt faktum att där finns hälften av CO2-utlsäppen – i Stilla-havs-regionen och Asien. Inte minst Kina.
Efter
Efter intervjun gjorde SVT ytterligare ett inslag där de frågade Peter Lundrgen om hans uttalande. De frågade också två experter, en naturgeograf och en meteorolog. Här klistrar jag in en snutt av vad experterna säger:

– Vi hade en kraftig uppvärmning fram till slutet av 90-talet. Därefter hade vi en relativt konstant temperatur i närmare 10 år, men sen har temperaturen fortsatt att stiga, ganska mycket dessutom.
Peter Lundgren angav att källan till hans uttalande om 18 år är en artikel och paneldebatt på norsk TV. I Temperaturen på kloden har stått stille i 18 år sägs det att
På begge sider av debatten er forskerne enige om at det ikke har vært noen tydelig temperaturøkning de siste 18 årene.
Den norske Nobelpristagaren Ivar Giæver säger dessutom såhär:

Stämmer det då?
Jag undersöker hur det ligger till med temperaturen. Passar samtidigt på att lära mig om hur vi mäter temperatur, och repeterar statistisk analys.
Den norska sidan refererar till datasamlingen HadCRUT4. Den är tillhandahållen av ett brittiskt universitet och bygger bl.a. på data från den brittiska nationella värdertjänsten. I datamängden ingår genomsnittstemperaturer månadsvis för hela jordytan (ytvatten och ytluft). Man kan också få temperaturan för jorden uppdelad i stora rutor.
Titta på data
Här är ett punktmoln för datat som Lundgrens källa refererar till. Varje punkt är ett månadsgenomsnitt ur HadCRUT4. Jag tycker inte det är tydligt att temperaturen ökar i perioden bara av att titta på datat. Jag har medvetet valt ut ett intervall där det är minst tydligt att det finns en positiv trend. Istället för de 18 åren 1997-2014, tar jag åren 1998-2012.
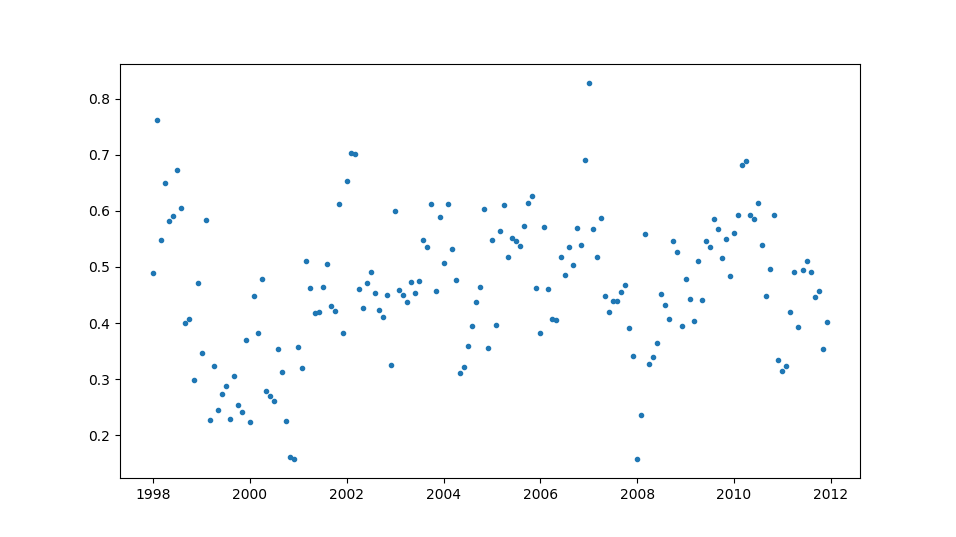
Jag testar två sätt att detektera trender. Det första är att anpassa en mjuk kurva till datat. Det andra är statistik analys av linjär regression. Linjär regression går ut på att anpassa en rak linje till punkterna. I figuren ritar jag ut både regressionslinjen (mer om den senare) och den jämna kurvan:
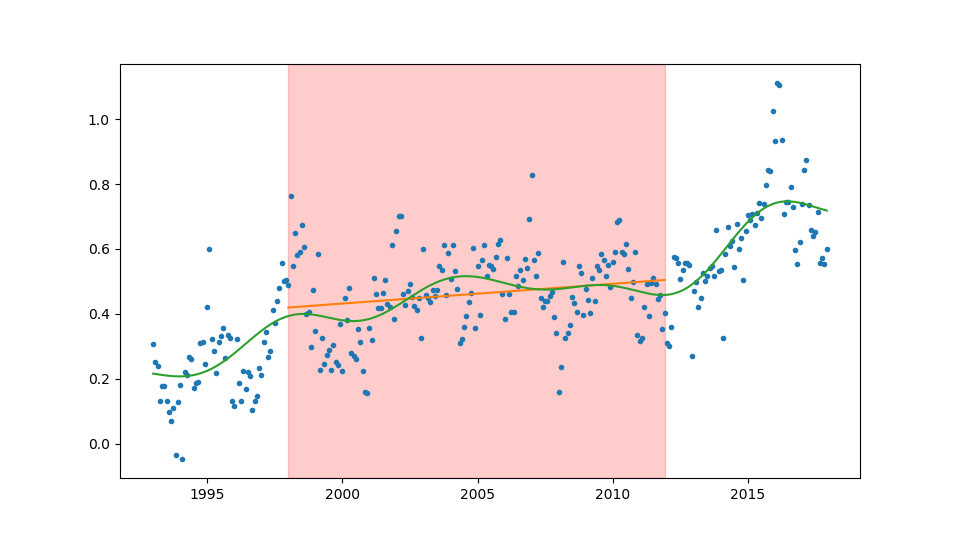
Här blir det lite tydligare att regressionslinjen (orange) och den utjämnande kurvan (grön) trendar uppåt inom intervallet (genomskinligt rött). Jag skapade den mjuka kurvan genom ett Butterworthfilter. Här spelar det nästan ingen roll vilket filter man använder, vi vill bara att det ser ut att följa datapunkterna.
Statistik analys
För att den statistiska analysen ska fungera behövs lite andaganden. Jag antar att årsmedeltemperatur \(Y\) beror på år \(X\) som \(Y = \alpha X + \beta + N\) där \(N\) är oberoende normalfördelat brus. \(\alpha\) och \(\beta\) är okända konstanter. Om vår modell kommer fram till att \(\alpha\) sannolikt är större än \(0\), betyder det att linjen har en positiv lutning, och att temperaturen antagligen ökar med åren inom intervallet.
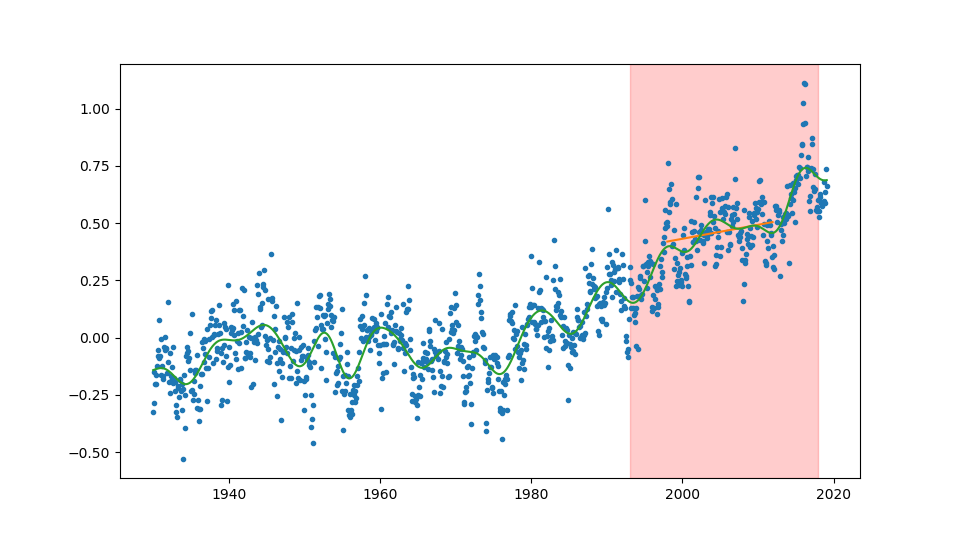
Här är en annan bild med ännu mer klimatdata. Det förra bildens intervall är utritat, och den allra första bildens räta linje syns svagt i orange:
Här är vad statistikboken säger (\(\alpha, \beta\) betyder samma sak som i den här texten. \(\alpha^{*}, \beta^{*}\) är [minsta-kvadrat]skattningarna som jag redan har använt för att rita linjen. \(s\) är stickprovs-standardavvikelsen, \(s=\sqrt{\frac{1}{n-2}\sum_i(y_i-y_i^{*})^2}\), där \((x_i, y_i)\) är mina punkter, och \(y_i^{*}\) är vad \(y\)-punkterna borde vara enligt modellen om allting låg på regressionslinjen. \(n\) är antalet punkter, \(S_{xx}\) är \(\sum_i{(x_i-\overline{x_i})^2}\). \(t\) är en känd fördelning som blir mer och mer lik normalfördelningen ju fler punkter vi har. Vi har många punkter, så det borde gå lika bra att ta normalfördelning):

Iden är att vi med satsen kan räkna ut ett intervall inom vilket \(\alpha\) befinner sig t.ex. med \(95\%\) sannolikhet. Eller räkna ut hur sannolikt är få det ett minst lika extremt resultat om \(\alpha=0\)?
Den här typen av hypotestester finns färdigimplementerade i statistikbibliotek. Språket R har en massa statistikbibliotek, men då måste jag lära mig hur man läser in datat. Jag testar Python istället som har scikit.learn. Det borde duga för det jag vill göra. Om jag vill förstå vad jag gör, eller inte hittar det som passar är det inte svårt att skriva själv, men ett standardbibliotek borde vara fritt från fel.
Så här använder jag scikit.learn:
lg_results = sci_stats.linregress(X, Y)
regress_line = X*lg_results.slope + lg_results.intercept
p_value = lg_results.pvaluep_value blir sannolikheten att vårt \(\alpha^{*}\) är så stort eller större under antagandet att \(\alpha\) egentligen är 0. P-värdet är för det här fallet \(p\approx 0.009\) för det minsta intervallet på \(14\) år. För det fulla intervallet på \(18\) år, är p-värdet \(\approx 6\cdot 10^{-5}\), dvs försvinnande litet.
Vad betyder det egentligen?
Vi har ett matematiskt resultat, att en viss sannolikhet är \(p\approx 0.009\). Men betyder det någonting i verkligheten? Kan man verkligen dra slutsatsen att det har blivit varmare under perioden? Jag har gått igenom teorin i statistikboken som bilden ovan kom ifrån. Det jag har räknat fram är följande matematisk process:
- Någon annan väljer \(\alpha, \beta, \sigma\) utan att tala om dem för dig. Du ska ta reda på hur osannolikt det är att \(\alpha=0\).
- Du får se \(15\cdot 12\) oberoende punkter \(y_i\) som slumpas ur fördelningen \(\sim N(\alpha \cdot x_i + \beta, \sigma)\) där \(x_i\) går från \(1998\) till \(2013\) med steg på \(1/12\).
- Du räknar ut \(\alpha^{*}\) med minsta-kvadratmetoden.
- Du räknar ut \(s, S_{xx}\) med formlerna ovan.
- Du räknar ut \(R_\alpha=\frac{\alpha^{*}-\alpha}{s\sqrt{\frac{\sum_i{x_i^2}}{nS_{xx}}}}\) i punkten \(\alpha=0\).
- Om \(\alpha\) som valdes i steg 1 verkligen var \(0\), ska detta värde komma ur en \(t(n-2)\)-fördelning. Dvs om vi gör om steg 2-5 många gånger, kommer \(R_\alpha(\alpha=0)\) dras ur \(t(n-2)\). Det vi kallar \(p\)-värde är sannolikheten att en \(t(n-2)\)-fördelad variabel har värdet \(R_\alpha(\alpha=0)\) eller högre. Vi låtsas som att månads-medeltemperaturna egentligen är oberoende (verkligen inte sant) och \(N(\alpha \cdot x_i + \beta, \sigma)\)-fördelade (troligen inte heller sant; de har åtminstone års-variationer). Det är så vi fick \(p\approx 0.009\).
TODO vad heter \(R_\alpha\)-variabeln? Såna saker med känd fördelning heter nånting som jag inte minns, och det står inte på svenska Wikipedia.
Normalisera X
Vår skattning \(\alpha^{*}\) har variansen \(\sigma^2\frac{\sum_i x_i^2}{nS_{xx}}\). Om man translaterar \(X\) ett visst antal år i någon led, är det rimligt att resultat och skattningar inte borde ändras. Men de gör det: säg att vi flyttar med \(A\) år i positiv riktning, dvs \(x^{'}_i=x_i+A\). \(S_{x'x'}=S_{xx}\), men variansen på \(\alpha^{*}\) blir \[\sigma^2\frac{\sum_i (x_i+A)^2}{nS_{xx}} = \sigma^2\left( \frac{A^2 + 2\overline{x}A}{S_{xx}} + \frac{\sum_i x_i^2}{nS_{xx}} \right)\]
Slutsatser
Jag tycker att man tydligt kan dra slutsatsen att det har varit en temperaturökning under perioden. Jag är varken klimatvetare eller statistiker, men jag har redovisat hur jag har tänkt och försöker inte luras. TODO: skriv att jag trodde att jag skulle få ett annat resultat!
Hur går det ihop med nobelpristagaren som säger att CO2-utslippene icke er så viktiga for klimaet? Och att teorien om att CO2 är så viktig avkreftes?
Jag har två förklaringar:
- Jag har missförstått statistiken - att göra regressionsanalys på det sättet jag gjorde med månadsdata är fel
- Ivar Giæver menade att vi inte har fått samma ökningarna som klimatmodellerna förutsåg, alltså är klimatmodellerna fel. Att det har varit en pyttelitet ökning under 18-års-perioden spelar ingen roll, för att det som förutsågs var mycket större.
TODO: Skriv om Peter Lundgren och att han borde ha kollat upp bättre, inte letat nyheter som kanske bekräftar världsbilden.
Vad har vi antagit?
Att temperatur har ett linjärt samband med år. Det behöver ju inte vara sant. Den kan öka (och ökar) enligt en helt annan form. Här är en figur över utjämnad temperatur de senaste 50 åren, inte alls linjärt: TODO figur. CO2-koncertrationen ökar linjärt under perioden. TODO figur, TODO - resonemang om varför det är CO2-koncentrationen som är viktig.
Att felen är normalfördelade - rätt säkert att det är ett OK antagande, eftersom det är temperatur vi pratar om. Alltid normalfördelad :-)
Är våra antaganden helt uppåt väggarna då? - Tror inte det. Tror man kan dra slutsatsen att det finns en positiv trend.